9 Questions to Ask When (Continuously) Deploying Microservices

Richard Li
Modern applications are systems, not just code. These applications are built from many different parts. For example, a modern application might consist of a handful of microservices (containing business logic) that use ElasticSearch (for search), Redis (for caching), and a PostgreSQL instance (for data storage).
In this applications-are-systems world, existing deployment systems start to show their age. A previously simple task such as installing your application for local development now becomes a long Wiki document with dozens of steps to setup and configure dozens of different components.
An aging deployment system will impact your agility and responsiveness:
- Developers will batch changes, and deploy less frequently, because deployment is “too much work.”
- Deploying a new service is expensive, so developers will opt to bundle more functionality into an existing service (creating bigger “micro”-services)
- Rollback of a software bug in production takes a long time, impacting end users and adding more disruption to development
Ultimately, an aging deployment system will hinder your ability to adopt continuous deployment — even if you adopt microservices. So if you want to do continuous deployment of microservices (or of any cloud application), what questions do you need to answer?
Developers
In a microservices architecture, developers tend to be the primary users of your deployment system (unless you want developers filing tickets to push to production!). So, you want to be able to answer four questions.
1. How does a developer set up a development environment for a service?
For local development, a popular choice is running your services in local Docker containers, and to use Docker Compose or minikube (if using Kubernetes in production) to quickly set up your entire application and its dependencies. This approach requires Dockerizing all dependencies, as well as providing a way for developers to edit code in a Docker container (e.g., mount a host folder into a container). Another popular strategy has developers code locally, and connect to a shared cloud infrastructure for all dependencies. This approach reduces the amount of local setup, but makes it easier for a single bug to impact multiple developers by reducing isolation.
2. How does a developer deploy a new service from development into production? What about a service update?
Whether or not your organization has embraced continuous deployment, creating an automated workflow to move code from development into production is essential. Here is a typical workflow:
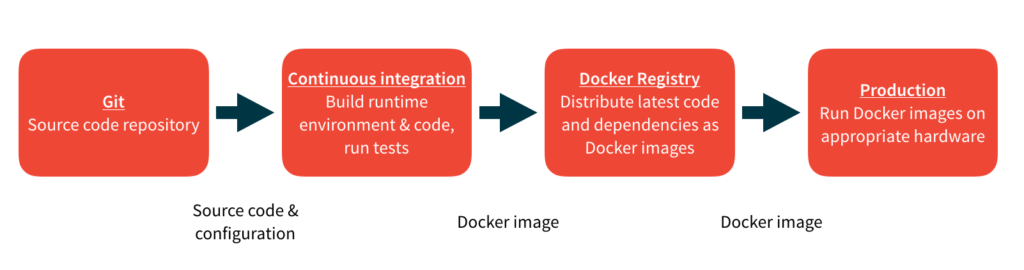
One of the key considerations in building a pipeline is environmental parity — insuring that all of your environments from development to continuous integration to production are all as similar possible. Nothing is more frustrating to debug than code that works in one environment and doesn’t work in another environment. For example, you may want to use a Dockerized database for development and CI, while using Amazon RDS for production.
3. How does a developer find out if a service is not working?
Every time a change is pushed to production, there is the risk of an error. Defining the process for identifying and escalating production issues is critical. Some organizations prefer to centralize monitoring with an on-call organization, which then escalates issues to development. Other organizations assign developers on-call responsibilities.
In addition to the process, basic tools for monitoring and debugging need to be put in place. A typical microservice deployment will include a metrics-oriented monitoring solution (e.g., Prometheus) and a log collector/aggregator (e.g., the Elastic Stack (https://www.elastic.co/products)). As the number of microservices expands, adding tracing information (e.g., OpenTracing) to your log metadata also becomes important.
4. How does a developer rollback? When a bug gets pushed into production, how do you quickly rollback to an older version?
When a bug is pushed into production, rollback is frequently the best option for end users. In a modern deployment system, a simple, robust rollback mechanism is essential. While a simple code change might be easy, rollbacks of dependent changes and/or database state add significant complexity.
The rollback mechanism is closely tied to the deployment strategy used (see below).
DevOps
Developers are not the only users of a deployment system. DevOps — the team that typically is responsible for your runtime infrastructure — also is a user of the deployment system. So, you also want to be able the following questions.
1. What environments need to be supported?
A deployment system needs to support multiple environments: development, staging, and production. Production itself may be multiple environments. For example, there may be different production environments based on geography or customer tier. Your cloud application needs to run in every supported environment.
2. What information is needed from developers to deploy a service? How are configuration and secrets handled?
When a service is deployed, a developer must communicate some essential configuration information to the runtime environment. For example, a service may have dependencies, e.g., a database. The database itself is deployed separately from the service, so the runtime environment must be able to provide a database and the service must be able to locate that database. Another class of configuration information is runtime configuration such as the number of instances or ports to be used. A service may not support multiple instances, in which case it needs to be deployed as a singleton. Other services may require high availability, and require multiple instances.
3. What deployment strategies should be used in deploying a service?
Deployment strategies impact the end user experience when updating and rolling back services. Destroying old services and recreating them may be the most efficient way to roll out updates. This strategy may have negative end user impact, as the update process may be visible to end users or rollbacks may take too long when services get rebuilt. More incremental strategies such as blue/green deploys or canary rollouts provide a more gentle way to rollout / rollback new updates and let you realize the promise of continuous deployment with minimal user impact.
A few final questions
If you don’t have great answers to these questions, your deployment system may be a hidden tax on your development velocity. But before you go and start building a new deployment system, here are some additional questions to consider.
1. What are the primary goals for your deployment system?
This can be a complicated question. For example, one goal of a deployment system is to improve DevOps efficiency and reduce operational cost. Another is to improve developer productivity by reducing the work a developer needs to do to deploy. Another could be continuous deployment. While all of these goals are compatible, picking a specific, incremental goal for your deployment system can result in a more focused initiative.
2. How do you expect your testing strategies to evolve to better support microservices?
Testing strategies for microservices vary widely. Individual testing of a specific microservice is a well understood activity, as each service is essentially a self-contained web application with its own API. Integration testing of microservices, however, is a fledgling field. We’ve seen two general classes of testing strategies for microservices: deployment-oriented and production-oriented. Deployment-oriented strategies involve pushing changes to a staging/QA environment, where integration testing is conducted. Production-oriented strategies involve engineering resilience (via circuit breakers) into microservices, with robust monitoring and logging infrastructure.
Questions?
We’re happy to help! Learn more about microservices, start using our open source Edge Stack API Gateway, or contact our sales team.